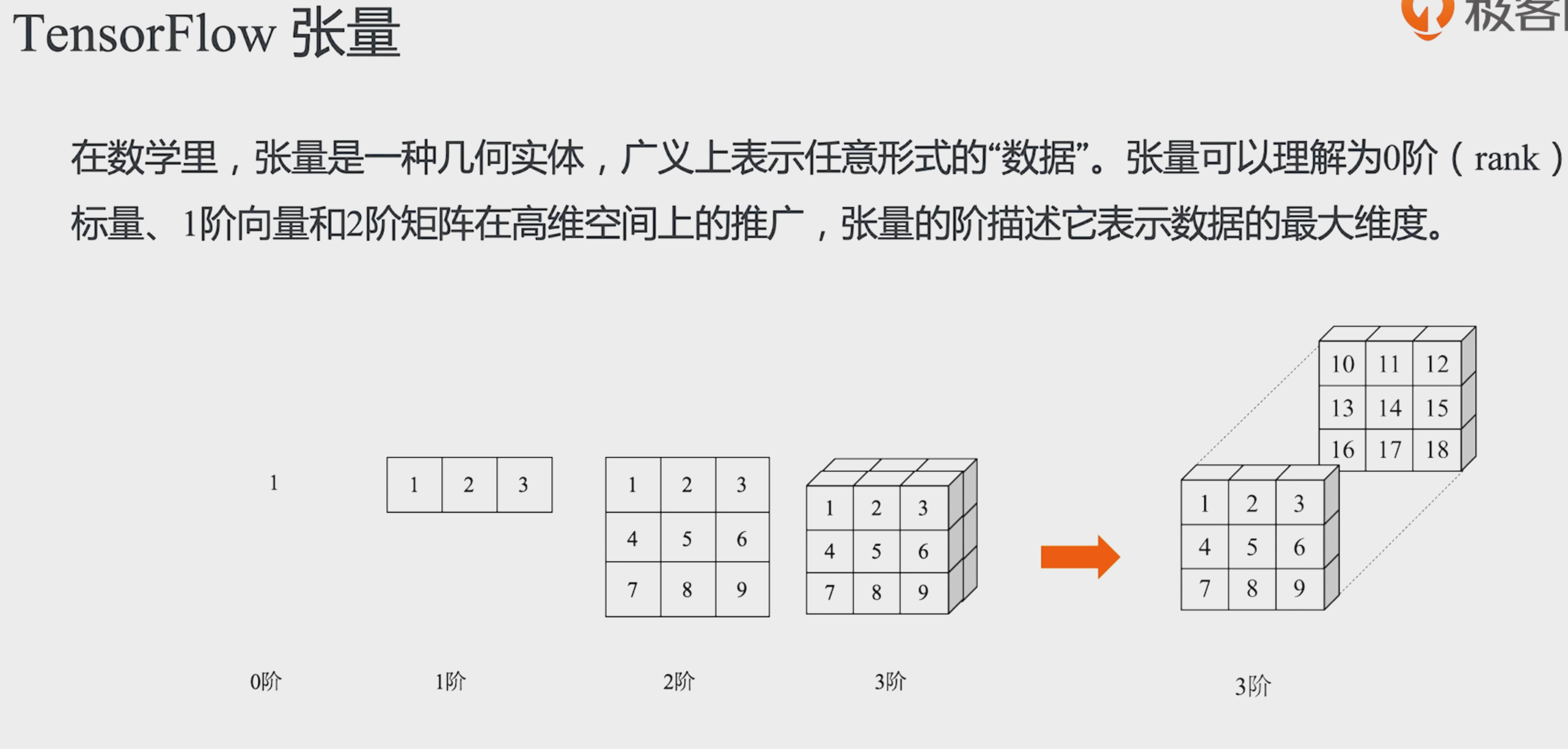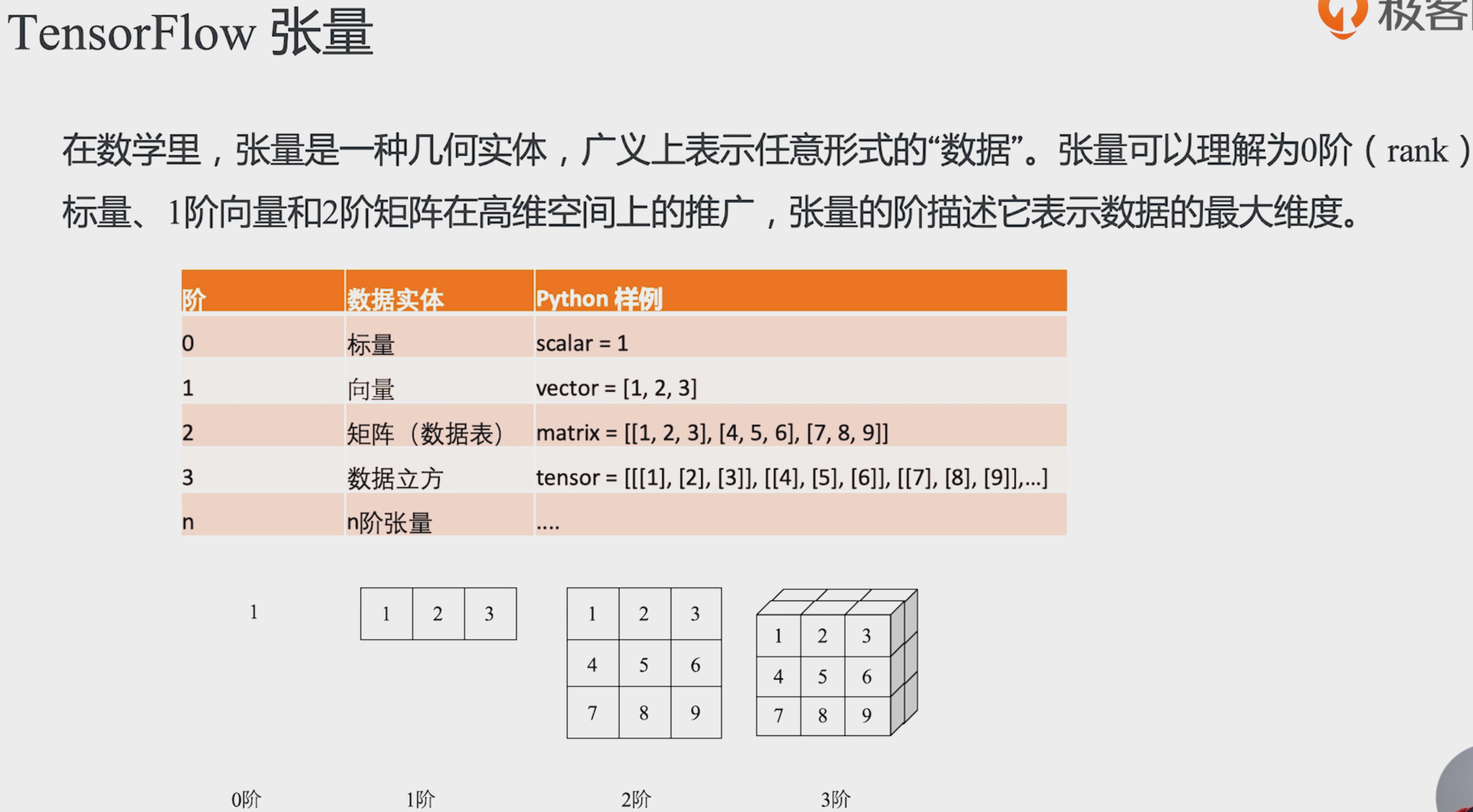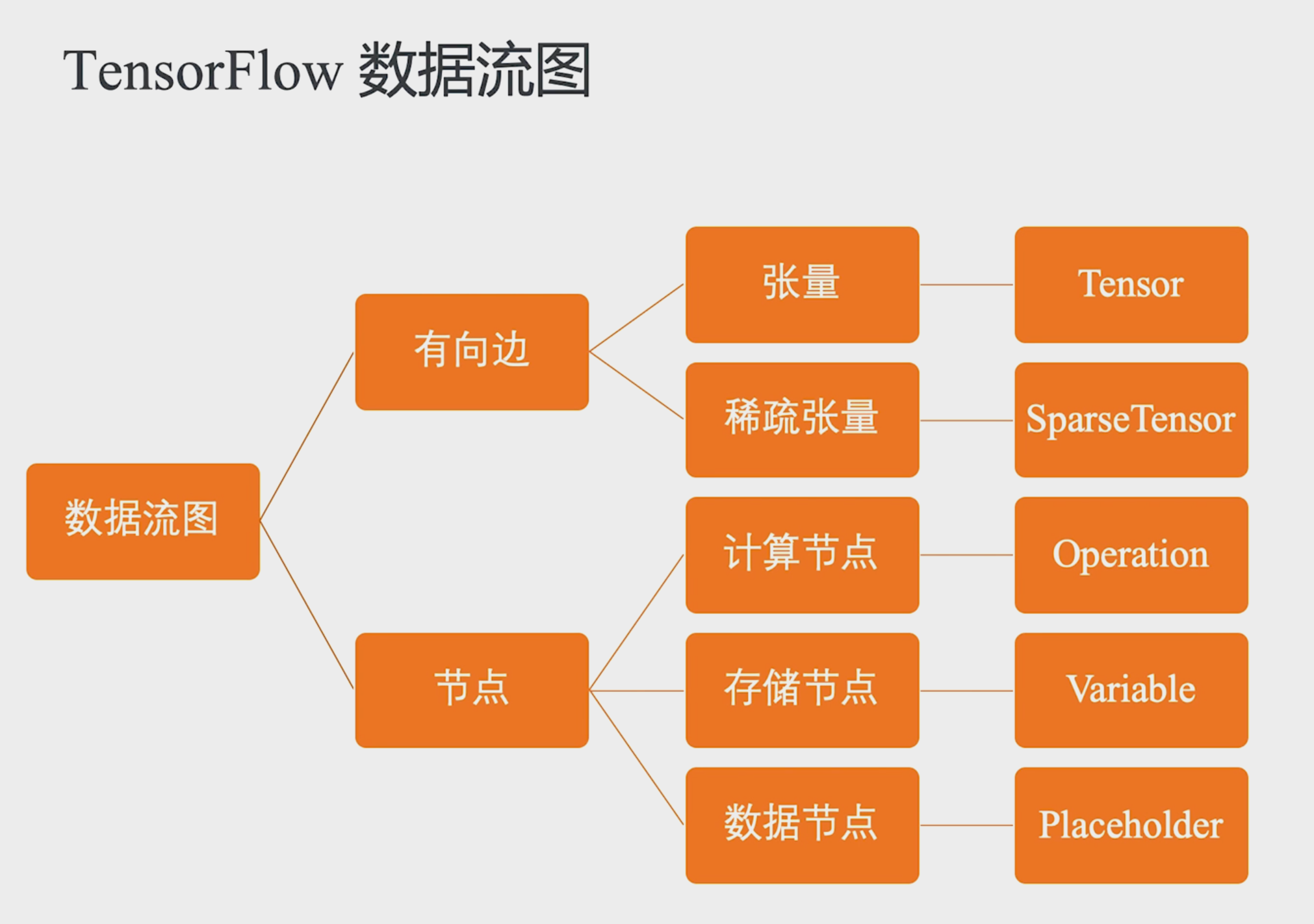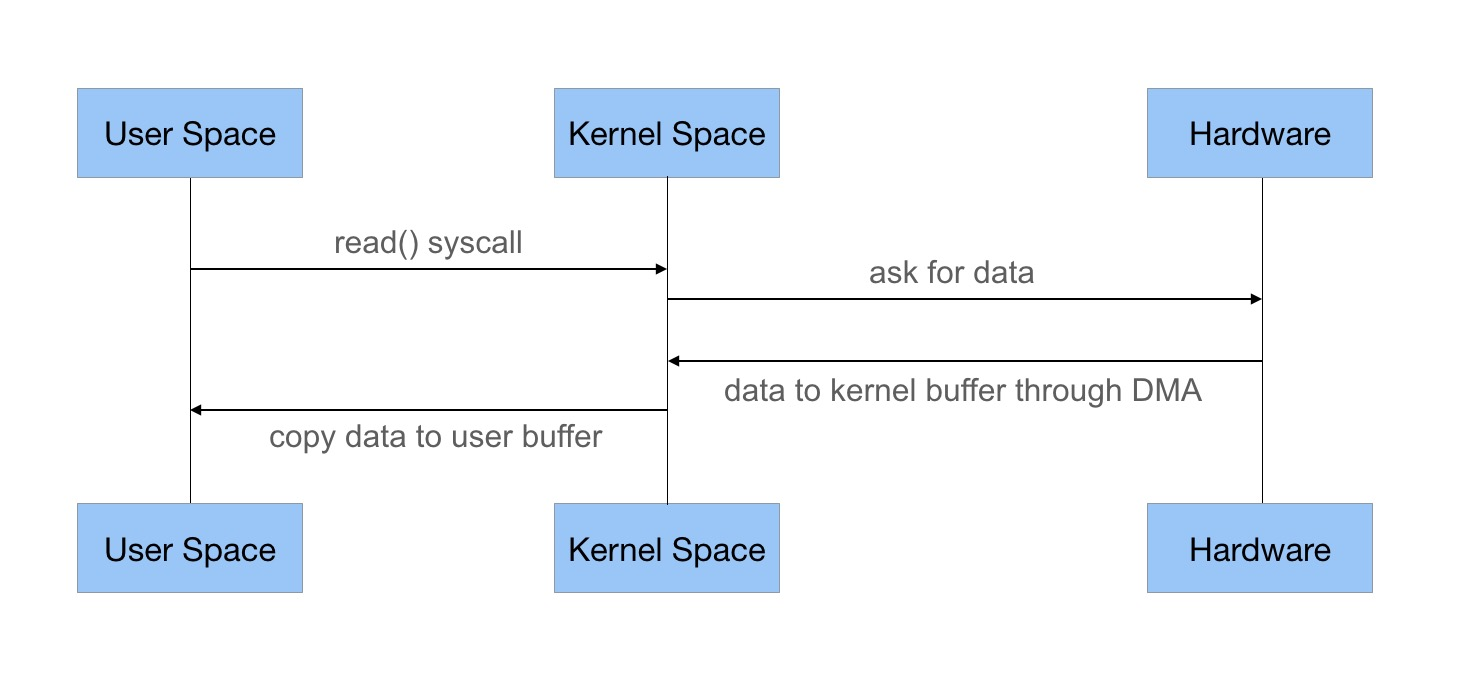
Java stream
发表评论
444 views
作者文章归档:wangxiuwen
常听人说,在32位的机器上对long型变量进行加减操作存在并发隐患,到底是不是这样呢?
非volatile类型的long和double型变量是8字节64位的,32位机器读或写这个变量时得把人家咔嚓分成两个32位操作,可能一个线程读了某个值的高32位,低32位已经被另一个线程改了。所以官方推荐最好把long\double 变量声明为volatile或是同步加锁synchronize以避免并发问题。
https://docs.oracle.com/javase/specs/jls/se8/html/jls-17.html#jls-17.7

JVM OOM 排查 - 简书 求树的左视图 mysql索引详解
最近阅读
https://gitee.com/lagouedu/Java_L2_2019.12.23 | java高薪训练营2019.12.23: Java高薪训练营 https://www.lagou.com/lgeduarticle/49826.html | 2019滴滴java面试总结 (包含面试题解析) https://juejin.im/post/6844904122160775176 | 图解Spring解决循环依赖♻
讲一下 Reactor、Proactor线程模型
RMI中对数据对象的序列化采用的是Java序列化。而目前主流的微服务框架却几乎没有用到Java序列化,SpringCloud用的是Json序列化,Dubbo虽然兼容了Java序列化,但默认使用的是Hessian序列化。
Java序列化的缺陷
1.无法跨语言
2.易被攻击
攻击者可以创建循环对象链,然后将序列化后的对象传输到程序中反序列化,这种情况会导致hashCode方法被调用次数呈次方爆发式增长, 从而引发栈溢出异常。例如下面这个案例就可以很好地说明。
Set root = new HashSet();
Set s1 = root;
Set s2 = new HashSet();
for (
链表长度大于8而且整个map中的键值对大于等于MIN_TREEIFY_CAPACITY (64)时,才进行链表到红黑树的转换
//-----------------------------------------------
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table)